
Prozessorientiertes Datenqualitätsmanagement
Datenqualität in Geschäftsprozessen
Die Bedeutung einer hohen Datenqualität herrscht heute Einigkeit. Auch die Notwendigkeit von Datenqualität für die Durchführung von Geschäftsprozessen wird allgemein anerkannt.
Jedoch befassen sich die Unternehmen immer noch überwiegend damit die Daten in ihren Reporting und Business Intelligence Applikationen zu verbessern an statt die Probleme dort anzugehen, wo sie auftreten – in den Geschäftsprozessen.
Es ist einfach dort zu beginnen wo die schlechte Datenqualität sichtbar wird – im Reporting – aber bis dann ist auch bereits der größte Schaden durch schlechte Datenqualität entstanden:
- Prozessunterbrechungen
- Mehr- und Doppelarbeit
- Fehlendes Vertrauen in die Daten (und Prozesse und damit auch den Reports)
Das prozessorientierte Datenmanagement legt seinen Schwerpunkt dagegen auf die Prozesse in denen Daten entstehen, genutzt, verändert und auch deaktiviert werden – es entwickelt sich dabei von der eingeschränkten Governance von Stammdatenobjekten zu einer Governance von Geschäftsobjekten und Geschäftsobjektattributen.
Prozessorientierung
Die REFA definiert den Begriff Prozessorientierung wie folgt
„Prozessorientierung ist eine unternehmerische Grundhaltung, bei der sämtliche betriebliche Aktivitäten als Kombination einzelner oder verschiedener Prozesse angesehen werden. Im Sinne der Prozessorientierung werden die Handlungen des Unternehmens auf die Produktionsschritte anstatt auf das Produkt selbst konzentriert. Somit wird angenommen, dass die Produktqualität von der Qualität des Herstellungsprozesses bestimmt wird. Folglich handelt es sich bei einem fehlerfreien Produkt um das Ergebnis eines fehlerfreien Prozesses.“
Aus Sicht des Datenmanagements bedeutet dies, dass der Fokus vom Ergebnis im BI auf die Prozesse der datenerzeugenden Systeme gelenkt werden muß. Ist der Prozess (der Datenerstellung) unter Kontrolle, so ist auch das Ergebnis (Auswertung) richtig: gute Datenqualität ist somit ein „Abfallprodukt“ von überwachten Prozessen
Eine konsequente Ausrichtung des Datenqualitätsmanagements auf Geschäftsprozesse ermöglicht es die häufigsten Fragen der Vergangenheit: „Wo fängt man an und was muss unter Governance gestellt werden?“ zu beantworten.
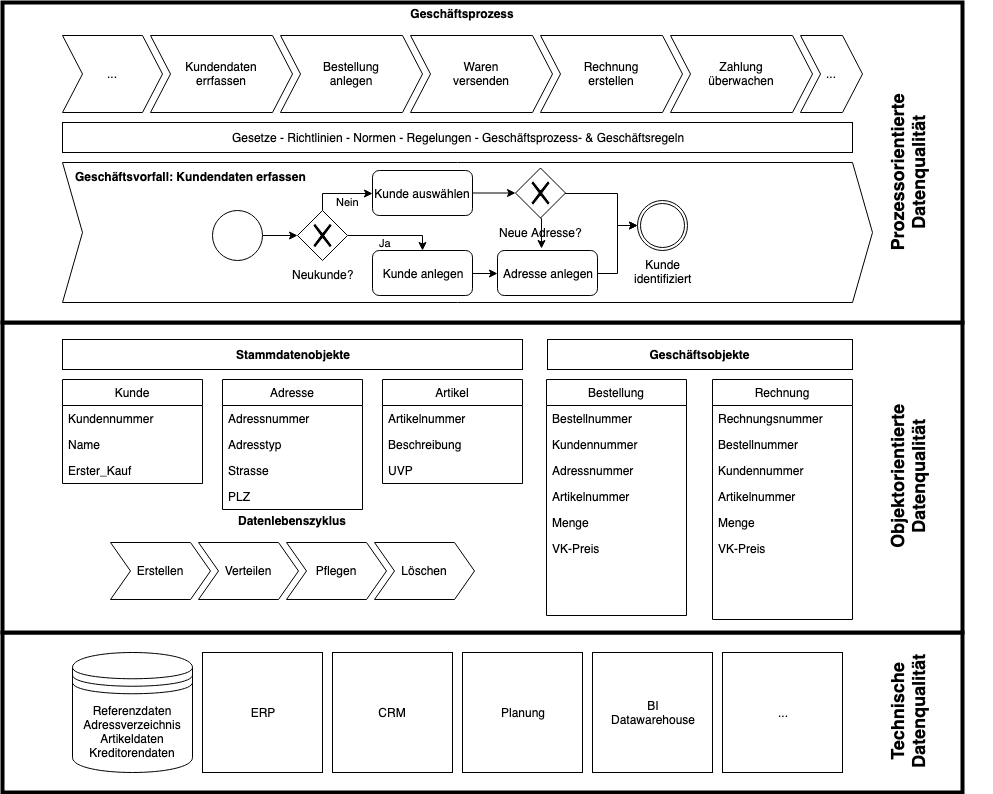
Die drei Ebenen der Datenqualität
Die Datenqualität kann aus unterschiedlichen Blickwinkeln betrachtet werden.
Die für prozessorientierte Unternehmen oberste Sichtweise ist die der Prozesskonformität der Daten, d.h. wie weit unterstützen die vorhanden Daten die definierten Geschäftsprozesse bzw. wo verursachen falsche, fehlende oder zu alte Daten Unterbrechungen. Diese Sicht fordert nicht, dass alle Attribute eines Geschäftsobjektes gepflegt sein müssen, sondern nur solche, die in diesem Geschäftsprozess benötigt werden. Die Prozesskonformität kann auf zwei Arten erreicht werden
- dem Datenqualitätsmonitoring das auf bereits erzeugte Daten angewandt wird
- dem aktiven Datenmanagement, zum dem auch das Stamm- und Referenzdatenmanagement gezählt wird, das fehlerhafte Daten bereits bei der Erzeugung identifiziert und verhindert.
Die mittlere Ebene beschreibt die klassische (Geschäfts)Objekt-orientierte Datenqualität, bei der die Attribute aus unterschiedlichen Blickwinkeln – Datenqualitätsdimensionen genannt – betrachtet werden. Diese Sicht eignet sich, um formale und syntaktische Fehler unabhängig von Prozessschritten zu überwachen.
Die unterste Schicht ist die technische Datenqualität: Sie überwacht den technischen Layer:
- haben die gespeicherten Daten die richtige Datentypen?
- werden Daten ohne Qualitätsverlust zwischen Applikationen und Datenbanken übertragen
- ist die Datenkonsistenz zwischen den unterschiedlichen Applikationen, Datenbanken oder Auswertungssystemen gegeben?
Der Weg zur Prozessorientierten Datenqualität
Wo beginnt man mit der Einführung von Datenqualitätsprogrammen in Unternehmen ist die wichtigste Frage.
Die ersten Ansätze kamen aus dem Stammdatenmanagement (engl. Masterdata Management MDM). Man identifizierte die kritischen und fundamentalen Geschäftsobjekte und bestimmte für diese dann die relevanten „prozessverhindernden“ Attribute. Die Probleme dieses Ansatzes bestanden dann darin, dass nur wenige Attribute während ihrer gesamten Lebenszeit „prozessverhindernd“ sind, sondern nur zeitweise in einem bestimmten Prozessschritt. Muss z.B. ein Formatfehler in oder das Fehlen einer Lieferanten-Steuernummer geheilt werden, wenn die letzten 3 Jahre dort kein Einkauf mehr erfolgte?
Das zweite Problem bestand darin das dieser Ansatz den Fokus auf Datenqualitätsregeln legte, die diese Attribute messen sollten ohne jedoch den Soll-Zustand ausreichend zu betrachten und zu dokumentieren. Das führte zu einer Regelflut durch die IT-Abteilungen, die den Bedarf der betrieblichen Nutzer konterkarierte. Noch problematischer waren Regeln, die nach bestem Wissen und Gewissen erstellt, aber dennoch falsch waren, da fachliche Zusammenhänge nicht bekannt waren und die so die Datenqualitätslage verzerrten.
Mit dem Aufkommen der Datenkataloge wurde dieser Ansatz aufgegeben und der Blick wurde auf die Datenobjekte – die Abbildung der Geschäftsobjekte in Applikationen und den zugrunde liegenden Datenbanken – gelenkt. Die Datenelemente und Feldbeschreibungen wurden aus den wertschöpfenden Applikationen wie ERPs, CRMs oder Planungssystemen in die Datenkataloge kopiert. Sie sollten dort mit Tags oder Labeln einen semantischen Layer bekommen. Dass ein solcher Ansatz bei Systemen mit >43.000 Tabellen händisch nicht funktionieren kann und auch KI-Unterstützung zwar hilfreich aber nicht allumfassend ist, versteht sich von selbst.
In einer Erweiterung wurden die Datenkataloge dann zu einem Metadatenmanagement umgebaut. Sie verfügten zwar jetzt über die Möglichkeit einer fachliche Aspekte zu dokumentieren, aber es fehlte immer noch eine Methode:
- wie Unternehmen die unterschiedlichen Elemente eines Datenqualitätsmanagements in die Fachabteilungen einführen sollten
- welche Datenmanagement Elemente von welchen Rollen benötigt und gepflegt werden
- wie ein Datenkatalog mit Funktionen bereits existierender Applikationen, z.B. Stammdatenmanagement, umgehen sollte
- wie die Schnittstellen zwischen Geschäftsprozessen, Regelungen & Richtlinien, Gesetzen und dem Datenmanagement aussehen sollte
Diese Methode wurde mit der prozessorientierten DQ entwickelt
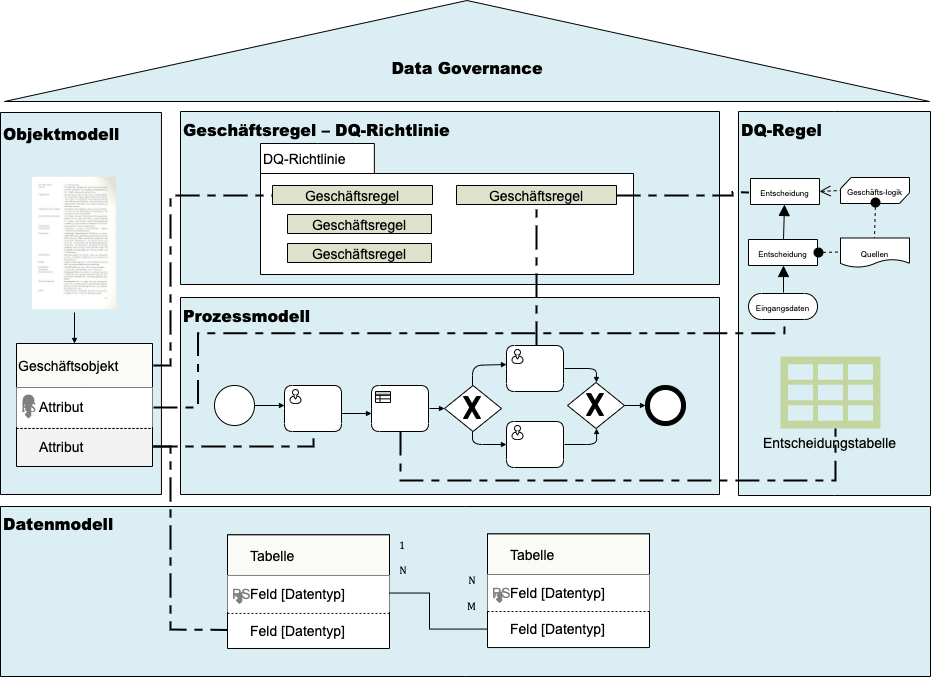
Im Mittelpunkt der Prozessorientierten Datenqualität steht eine detaillierte und dokumentierte Geschäftsvorfallsbeschreibung mit ihren Geschäfts- und Geschäftsprozessregeln. Diese Einzelschritte des Prozessmodells erlauben es, das Objekt- und Datenmodell abzuleiten und die Datenqualitätsregeln – dem Messen des Ist-Zustandes – oder Validierungsregeln – dem Steuern des Ist-Zustandes – zu definieren.
Geschäftsprozessregeln sind operative Regeln, die vorgeben, wie die Geschäftvorfälle ablaufen müssen. Sie sind die Grundlage für die Messung der Prozesskonformität.
Geschäftsregeln sind strukturelle Regeln. Sie beschreiben den Soll-Zustand eines Geschäftsobjektes oder Attributes. Dabei können sie unabhängig von einem Geschäftsvorfall sein. Geschäftsregeln sind die Grundlage für die objektorientierte Datenqualität.
Durch das Zusammenfügen von etablierten Notationen und die Nutzung erprobter Werkzeuge ist der Ansatz der prozessorientierten Datenqualität schnell einzuführen, einfach zu vermitteln und mit vorhandenen IT Werkzeugen umzusetzen.
Die folgenden Blog-Beiträge werden die einzelnen Komponenten der Prozessorientierten Datenqualität und deren Zusammenspiel detailliert beleuchten.