

Die Eisenhower – Falle
»Eine hohe Datenqualität ist die Grundlage für korrekte Entscheidungen«,
»Eine hohe Datenqualität ist wichtig für unterbrechungsfreie Geschäftsprozesse« »Ohne Daten keine Digitalisierung«.
Kein Unternehmen wird diesen Mantren widersprechen aber dennoch investieren die wenigsten Unternehmen in ein Datenmanagement Programm.
Während eines BBQs diskutierte ich darüber mit einem Bekannten, COO eines internationalen Life Science Konzerns, und seine Antwort kam wie aus der Pistole geschossen: „Verständlich, denn Datenmanagement steckt leider im falschen Eisenhower Quadranten »wichtig – aber nicht dringend«. Wir müssten auch mehr tun, aber es gibt nun mal immer wichtigere dringendere Aufgaben.“
Und wie erreicht Datenmanagement die Agenden der Unternehmen?
I. Durch einen Vor- oder Unfall
Die häufigste Art, um aus „nicht dringend“ „dringend“ zu werden, ist ein datengetriebener Unfall. Klassiker sind hier immer wieder
- fehlende Materialabmessungen und Gewichte oder falsche Mengeneinheiten, die einen Transport unmöglich machen oder extrem verteuern
- Reputationsverlust durch falsche Anreden in Marketing Dokumenten oder noch schlimmer der gestrandeten Regierungsairbus mit den falschen Notfall-Checklisten
- Lieferung per Rechnung an Adressen mit schnell wechselnden Bewohnern, z.B. Flüchtlingsheimen
- Firmenübernahme nach Einbruch der Aktie: ein Pharma – Unternehmen hatte bei der Datenmigration die Rezeptmengen verdoppelt.
Der Vorteil von Vor- und Unfällen ist, dass es keines Business-Case bedarf, sondern die Kosten meist direkt sichtbar werden.
II. Durch Gewalt
Nicht unbedingt körperliche aber gesetzliche in Form von Bußgeldern.
Zum Beispiel das Bundesdatenschutzgesetz (DSGVO) war lange ein zahnloser Tiger aber die neuen Bußgelder und vor allem deren Durchsetzung bewegt das BDSG gerade aus dem Eisenhower Quadranten „wichtig – nicht dringend“ nach „wichtig – dringend“. Damit kommt auch das Datenmanagement durch die Hintertür auf die Agenda, da zentrale Fragen sind:
- welche Daten haben wir gespeichert (logisches Datenmodell)?
- wo haben wir sie gespeichert (physisches Datenmodell)?
- wie sehen unsere Prozesse zum Umgang mit diesen Daten aus (Geschäftsprozess- und Geschäftsregeln)?
Zum Zusammenspiel dieser Komponenten siehe auch den Blog prozessorientiertes Datenqualitätsmanagement.
Sollte die Forderung der Europäischen Kommission Unternehmensdaten zu teilen ebenfalls nationales Gesetz werden wird das Wissen um die eigenen Daten noch viel wichtiger – zumal die geplanten Sanktionen noch höher als die 4 % Weltumsatz der DSGVO sein werden.
III. Als strategisches Projekt
Merger & Acquisition sind starke Treiber für ein einheitliches Datenmanagement. Selbst wenn die übernommene Firma ihre eigene IT Struktur behält wird eine Harmonisierung der Informationen benötigt (Konzeptuelles Datenmodell) und über ein gemeinsames Stammdatenmanagement, z. B. als Data-Hub, zum Konsolidieren von Kunden- und Lieferantendaten nachgedacht. Leider bleibt einer der wichtigsten Aspekte meist auf der Strecke: Das Konsolidieren von Begriffen – das Festlegen eines gemeinsamen Verständnisses in einem Glossar (ja ich weiß – wichtig aber scheinbar nicht dringend bis I. eintritt)
Der zweite wichtige strategische Treiber ist ein Plattformwechsel.
Neue Plattformen bieten die Möglichkeit zur Veränderung – und werfen die Frage auf, welche alten Verfahren und Informationen noch benötigt werden. Hier steigen die Migrationskosten schlagartig, wenn die bestehenden Prozesse, Regeln und Datenmodelle nicht ausreichend dokumentiert sind.
Ein weiterer Kostentreiber im Plattformwechsel entsteht, wenn zwar das Ziel bekannt ist, man aber feststellt, dass die Daten im alten System nicht so zur Verfügung stehen, wie man es angenommen hat. Getreu dem Motto: Mein ERP läuft auch mit schlechter Datenqualität gut. Jetzt entstehen erhebliche Mehrbelastungen, wenn gleichzeitig zur Migration auch noch Anwender aus dem Tagesgeschäft genommen werden müssen um diese Versäumnisse nachzubearbeiten.
Gerade Automatisierungsprojekte scheitern an diesem Aspekt der fehlenden oder falschen Daten regelmäßig.
IV. Schleichend und nicht als Programm
Strategische Datenmanagement Programme sind lang laufend, komplex, abstrakt, querschnittlich angelegt und daher kostspielig.
Kosten entstehen vor allem dann, wenn man als Unternehmen realisiert, dass die Grundlagen, wie Glossar oder dokumentierte Geschäftsregeln fehlen und man gar nicht mit „Datenqualität verbessern“ starten kann.
Wie soll man denn auch Datenqualität bewerten, wenn man nicht weiß, wie die Daten überhaupt aussehen sollen?
Man kann schrittweise die Datenqualität die steigern, wobei jede Stufe wieder der Eisenhower Bewertung unterzogen werden.
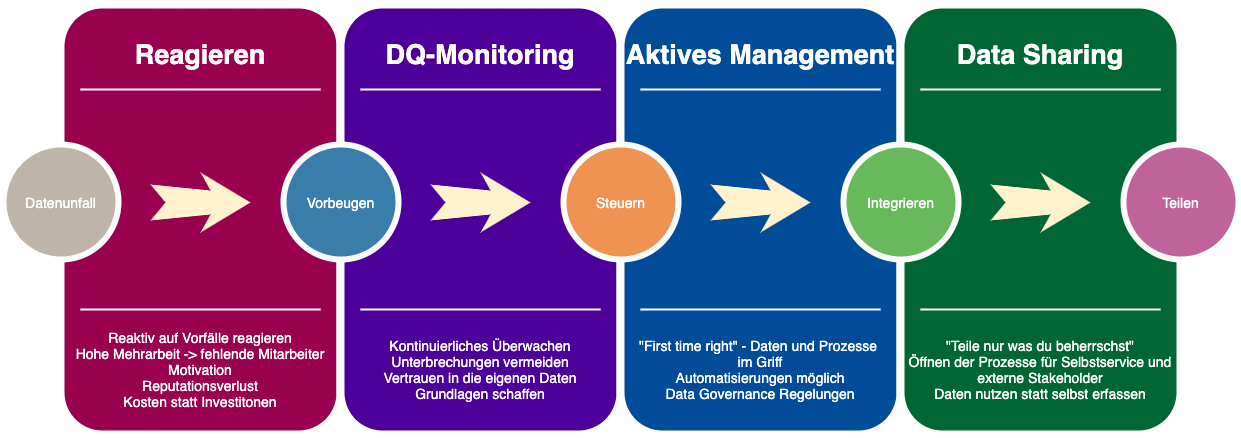
I. Reaktives Reagieren auf Fehler: Die mit Abstand teuerste Methode, aber die einfachste um in den richtigen Eisenhower Quadranten zu kommen.
Fehler entsteht – sorgt für eine Disruption – Fehler wird verbessert – Management fordert: Das darf nie wieder geschehen – Aktionismus bricht aus und alle ähnlich gelagerten Fehler werden abgestellt. Das ist der kritische Punkt, an dem ein Unternehmen entscheiden muss, ob es in finanzielle Vorlage für eine Datenqualitätsüberwachung geht oder die entstehenden Kosten für auftretende Fehler tragen möchte. Man hat ja immer die Hoffnung das keine weiteren Fehler mehr entstehen ….
II. Datenqualitätsmonitoring: Fehler identifizieren, bevor eine Unterbrechung stattfindet. DQ-Monitoring überwacht die relevanten wertschöpfenden Prozesse im Unternehmen und meldet Daten und Regelverstöße durch nachträgliche Messungen. Die erfolgreiche Einführung benötigt zwei Komponenten: eine fachliche Beschreibung des Sollzustandes (Prozessmodell, Geschäftsregeln, DQ-Regeln) und eine IT-Umsetzung zur kontinuierlichen Messung (Datenmodell, DQ-Monitoring Werkzeug). DQ-Monitoring kann parallel in verschiedenen Bereichen des Unternehmens eingeführt werden. Dazu empfiehlt es sich dann eine Organisationseinheit aufzustellen, das Data Governance Office, um die unabhängigen Projekte zu steuern und konsistent zu halten.
III. Aktives Datenmanagement: Steuerung des Datenmanagements mittels Data Governance. Geschäftsprozesse werden so modelliert, dass Fehler vermieden werden. Richtlinien zum Umgang mit Daten werden aufgestellt und überwacht. Die Herkunft und Verwendung der Daten wird protokolliert. Das Risiko durch fehlerhafte Daten wird minimiert. Neben strategischen Dokumenten wie einer Datenstrategie und einem Data Governance Rahmenwerk wird Zeit in das Redesign der Geschäftsprozesse fließen. Auf der IT Seite kommen Produkte wie Stammdatenmanagement (Master Data Management) und auch Referenzdatenmanagement dazu.
IV. Data Sharing: Die Prozesse eines Unternehmens sind so robust, dass man sie für Dritte öffnen kann. Die Öffnung kann intern, im Rahmen von Selbstservices sein, oder extern für weitere Marktteilnehmer, wie Lieferanten oder Kunden. Die Anforderungen variieren vom Einsatzzweck:
- Soll das Erstellen von eigenen Auswertungen ermöglicht werden, muss ein semantisches Datenmodell zwingend vorhanden.
- Steht die Pflege von Daten im Fokus, sind Workflow-gesteuerte Stammdatenlösungen hilfreich.
- Sollen externe Datenquellen eingebunden werden oder Daten für externe Beteiligte bereitgestellt werden, benötigt man ein semantisches Datenmodell, eine Übertragungsmodellierung, wie z. B. DCAT-AP und die Frage nach Datenhubs zur Verteilung in unterschiedliche Systeme stellt sich ebenfalls.
Datenarchitektur ist die Überschrift für diesen Reifegrad.
Fazit
Einen Use-Case für Datenmanagement zu schaffen wird nicht leicht gelingen – daher auf einen Daten- oder Prozessunfall warten oder mit einem strategischen Ereignis koppeln.
Und am besten unterhalb des Radars schon mal mit den fundamentalen Aufgaben der Dokumentation beginnen.